
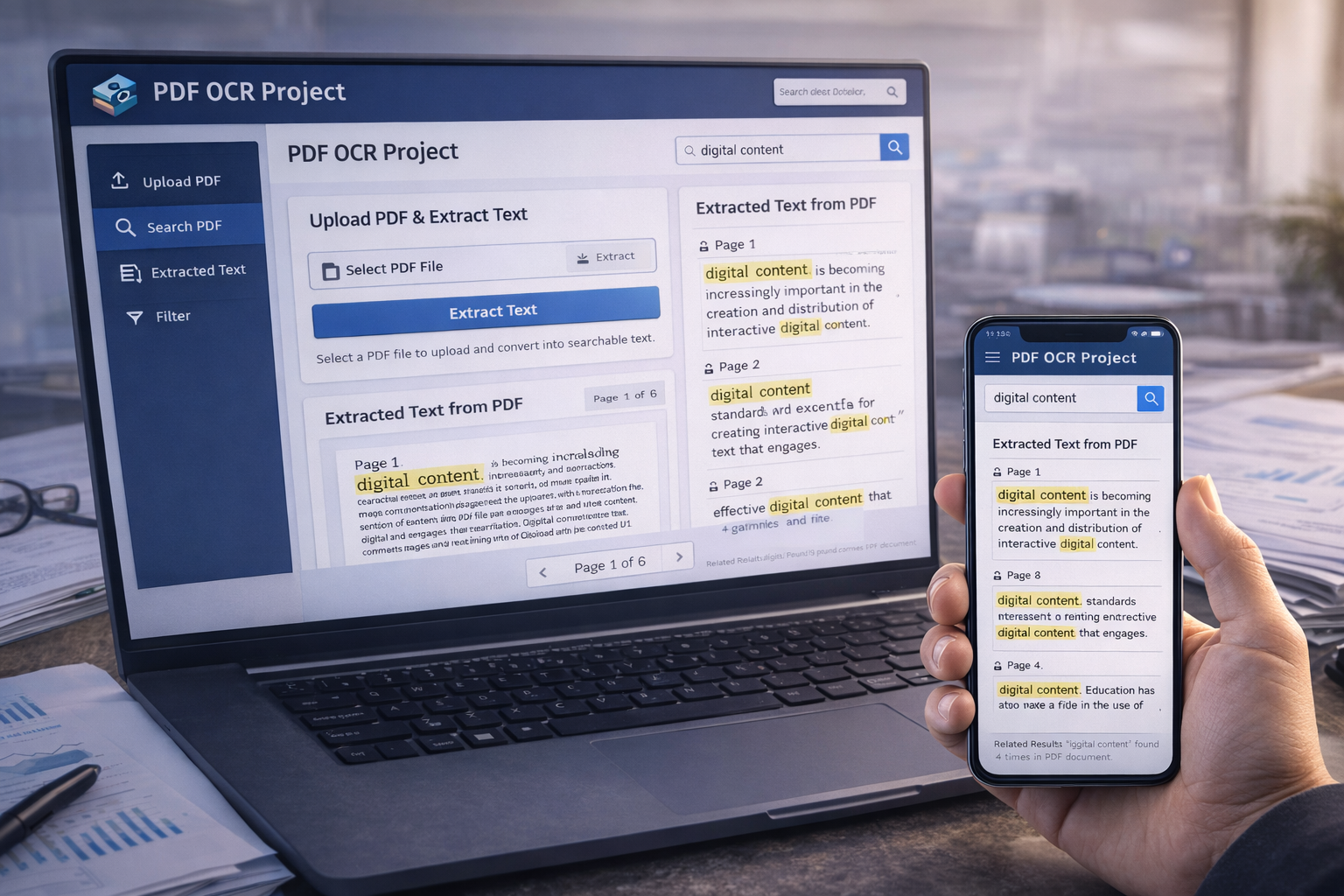
The PDF OCR Project utilizing Pytesseract is a project developed using Python, Django, Pytesseract, and OpenCV. Its main objective is to convert PDF pages into searchable text and allow users to perform text searches within the PDF content. The project utilizes Pytesseract, which is a Python library that integrates with Tesseract OCR (Optical Character Recognition) engine. Tesseract OCR is a widely used open-source OCR engine capable of recognizing text from images.
Platforms

Features
 It using Pytesseract with Python Django provides a user-friendly web interface to upload PDF files, convert them into searchable text, and perform text searches within the PDF content.
It using Pytesseract with Python Django provides a user-friendly web interface to upload PDF files, convert them into searchable text, and perform text searches within the PDF content.
It convenient solution for extracting information from PDFs and facilitating easy text-based searches.



